[I mentioned two weeks ago that I was working to dive into the practical uses of machine learning algorithms. This is the first of a series of posts where I show what I’ve been working on.]
The Pima Indians dataset is well-known among beginners to machine learning because it is a binary classification problem and has nice, clean data. The simplicity made it an attractive option. In what follows I’ll be mostly following a process outlined by Jason Brownlee on his blog.
The Pima Indian population are based near Phoenix, Arizona (USA). They have been heavily studied since 1965 on account of high rates of diabetes. This dataset contains measurements for 768 female subjects, all aged 21 years and above. The attributes are as follows, and I list them here since they weren’t explicitly stated in the version of the data that came with Weka and I only found them after a bit of digging online:
- preg - the number of times the subject had been pregnant
- plan - the concentration of blood plasma glucose (two hours after drinking a glucose solution)
- pres - diastolic blood pressure in mmHg
- skin - triceps skin fold thickness in mm
- insu - serum insulin (two hours after drinking glucose solution)
- mass - body mass index ((weight/height)**2)
- pedi - ‘diabetes pedigree function’ (a measurement I didn’t quite understand but it relates to the extent to which an individual has some kind of hereditary or genetic risk of diabetes higher than the norm)
- age - in years
This video gives a bit of helpful context to the data and the test subjects:
https://www.youtube.com/watch?v=pN4HqWRybwk
I also came across a book by David H. DeJong called “Stealing the Gila: The Pima Agricultural Economy and Water Deprivation, 1848-1921” which describes how the diverting of water and other policies “reduced [the Pima] to cycles of poverty, their lives destroyed by greed and disrespect for the law, as well as legal decisions made for personal gain.” It looks like a really interesting read.
The Problem
The idea with this data set is to take the attributes listed above, combine them with the labelling (i.e. we know who has been diagnosed with diabetes and who hasn’t) and figure out the pattern as much as we can. Can we figure out if someone is likely to have diabetes just by taking a few of these measurements?
The promise of machine learning and other related statistical tools is that we can learn from the data that we have to make testing more useful. Perhaps we only need your height, genetic risk factor and skin thickness to make such a prediction? (Unlikely, but still, perhaps…). If we emerge from our study with a statistical model, how well does it perform? How much can we generalise from the data? What would be an acceptable error rate in the medical context? Is it 80% or is it 99.99%? The former would save millions of dollars in test costs but would throw lots of errors; the latter would be highly accurate but it might be expensive to calculate the model.
The use case for this specific case would maybe be to identify at-risk individuals who are on the way to a diagnosis of diabetes and intervene somehow. Our motivation here is clear: people don’t want to be diabetic, so how early can we catch this transition? It would save governments money, expose fewer people to unnecessary tests and improve their quality of life.
I’m not a doctor, but to solve this problem manually would seem to require monitoring of blood tests (glucose and insulin levels), perhaps looking at exercise and diet, and also weight. At scale across the population of an entire country, for example, this seems like it might get expensive and/or too much for one person to process in their head. The data isn’t too large or complex, but it still seems to be useful you’d want to automate it to some extent.
There are some potential ethical issues around the data. Everything offered as part of the table of data is anonymised, but there are some outliers (see below) that I have to believe wouldn’t be too hard to find. The applicability of whatever model comes from this data will likely only have a limited application — the data is drawn only from women, after all. I also noticed that while the data is no longer available on the UCI Machine Learning Repository website, it still comes packaged with Weka. There was a notice on the UCI site (which I can no longer seem to be able to locate) stating that the permission to host the data had expired. It is unclear to me what’s going on with the permission there.
Data Preparation
Exploring the data using Weka’s explorer tool plus the attribute list above we can see that we have some blood test data, some non-blood body measurements and this genetic marker (presumably achieved through either blood tests or interview questions about family history). As I was working to understand the various attributes, it occurred to me that for this to be really useful, we’d want our model to work on data that wasn’t derived from blood tests; they’re expensive and they’re invasive. I didn’t get round to doing that for this round of exploration but it’d be high up on my wishlist next time I return to this data.
There are only 768 instances, so it’s still quite a small data set, especially in the context of machine learning examples. This is probably explained by the fact that it’s real medical data (so there are consent issues) plus the fact that it is several decades old and the processing power available then didn’t lend itself to processing mega-huge sets.
Thinking about what attributes might be removed to make a simpler model, I first thought that maybe the number-of-pregnancies might be dispensable, but then I thought to the number of hormonal and other changes that happen and I guess actually it is probably quite important.
There were some outliers in the data that I identified as needing further consideration / processing before we get our model trained:
- There were some women who had been pregnant 16 or 17 times. They were on the far edge of the long tail, but I ended up leaving them in for the model rather than deleting them completely.
- There were 5 people who had 0 as their result for ‘plus’, which seems to be an error. I decided to remove these.
- There were 35 people who had 0 as their blood pressure, which seems to be an error.
- There were 227 people with 0mm skin thickness. This is possible, but I think it’s more likely that no measurement was taken, at least for a lot of them.
- There were 11 people who are listed as weighing 0kg. That seems to be an error.
After I’d identified these various outliers I decided to make a series of transformations to the whole set. From this I’d emerge with three broad versions of the data:
- the baseline dataset, with nothing removed or changed
- the outliers removed completely and replaced with NaN values
- the outliers replaced with mean averages for each particular attribute
For each of these broad versions, moreover, I prepared three separate versions:
- all values normalised (ranges and values for all attributes transformed to being from 0-1 instead of being in their original ranges. i.e. maximum weight as 1 and minimum weight as 0 etc)
- all values standardised (set the mean for the data as being zero and the standard deviation to 1)
- all values normalised and standardised (i.e. both transformations applied)
Producing these various versions of the data was something I learned from Brownlee’s book, “Machine Learning Mastery With Weka”. It turned out to be somewhat fiddly to do in Weka. In particular, every time you want to open up a file to apply transformations the default folder it remembers is often several folders down in the folder hierarchy. By the ninth transformation (there were nine sets in total, by the end of this process) I was ready for a more functional / automated approach to these data conversions!
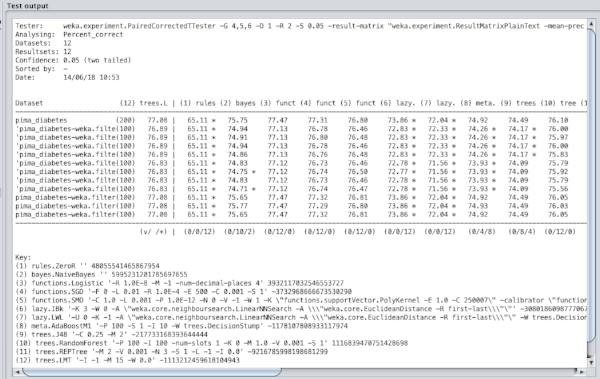
Weka does offer some nice tools for the initial exploration of the data. Here you can see two charts that are generated in the ‘explorer’ application. First we have a series of simple bar charts visualising all the individual attributes. Then we have a plot matrix showing how all the various attributes correlate to each other (or not, as was mostly the case for this data set).