Have you ever come across a PDF filled with useful data, but wanted to play around with that data yourself? In the past if I had that problem, I'd type the table out manually. This has some disadvantages:
- it is extremely boring
- it's likely that mistakes will get made, especially if the table is long and extends over several pages
- it takes a long time
I recently discovered a tool that solves this problem: Tabula. It works on Windows and Mac and is very easy and intuitive to use. Simply take your page of data:
Then import the file into Tabula's web interface. It's surprisingly good at autodetecting where tables and table borders are, but you can do it manually if need be:
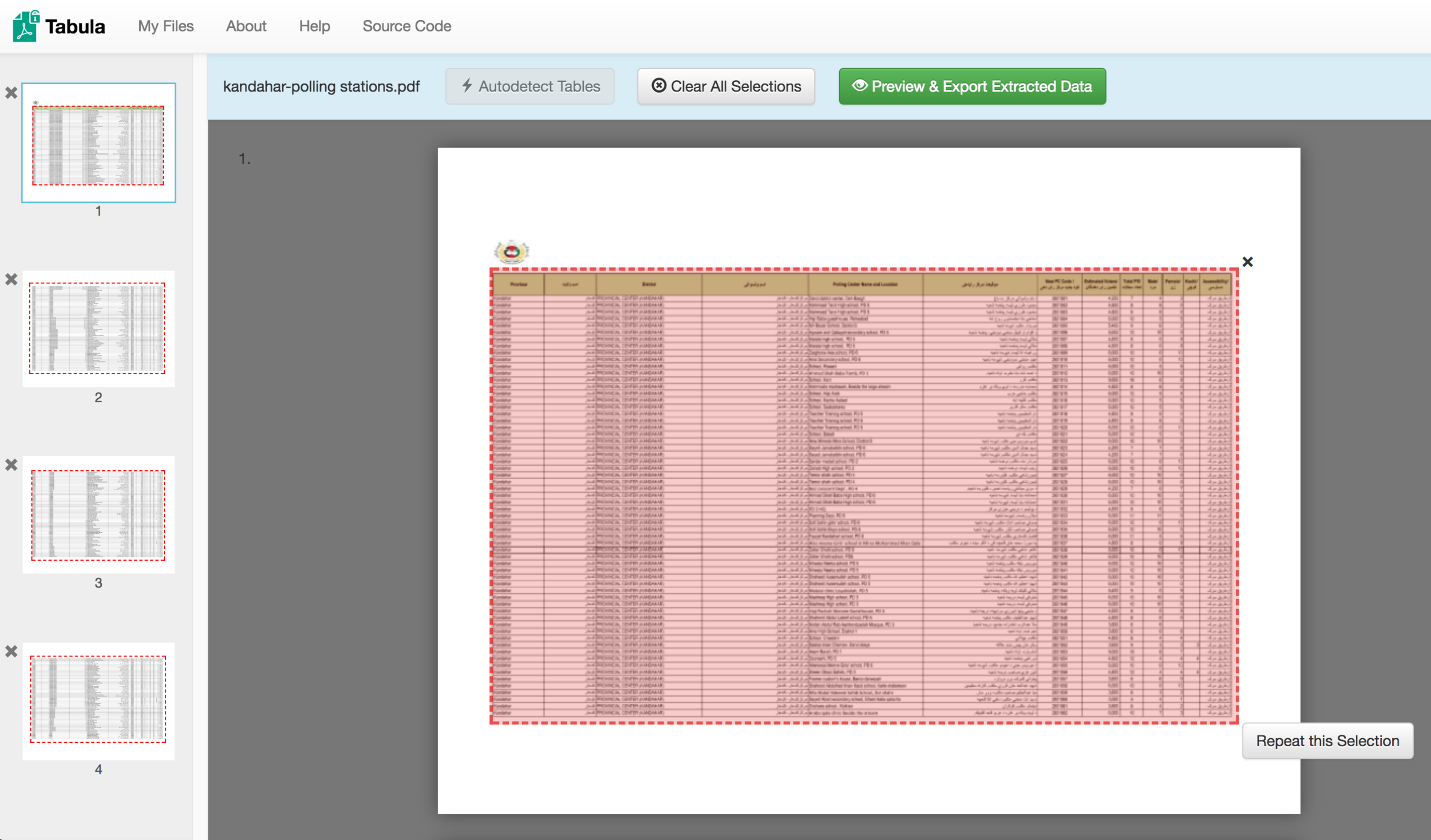
Then check that the data has been correctly scraped, select formats for export (from CSV to JSON etc):

And there you have it, all your data in a CSV file ready for use in R or Python or just a simple Excel spreadsheet:

Note that even though the interface runs through a browser, none of your data touches external servers. All the processing and stripping of data from PDFs is done on your computer, and isn't sent for processing to cloud servers. This is a really nice feature and I'm glad they wrote the software this way.
I haven't had any problems using Tabula so far. It's a great time saver. Highly recommended.