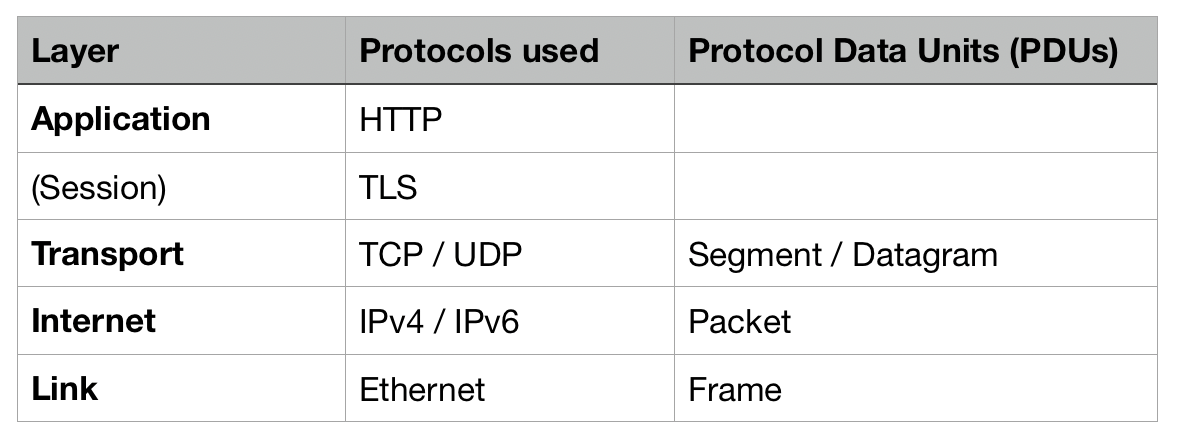
Physical Layer
Before we get into the realm of protocols, it's worth remembering and reminding ourselves that there is a physical layer on which all the subsequent layers rely. There are some constraints relating to the speed or latency with which data can be transmitted over a network which relate to fixed laws of physics. The most notable of those constraints is the fact of the speed of light.
Link Layer — Ethernet
Ethernet is the protocol that enables communication between devices on a single network. (These devices are also known as 'nodes'). The link layer is the interface between the physical network (i.e. the cables and routers) and the more logical layers above it.
The protocols for this layer are mostly concerned with identifying devices on the network, and moving the data among those devices. On this layer, devices are identified by something called a MAC (Media Access Control) address, which is a permanent address burned into every device at the time of manufacturing.
The PDU of the Ethernet layer is known as a 'frame'. Each frame contains a header (made up of a source address and a destination address), a payload of data, and a footer.
Internet Layer — The Internet Protocol (IPv4 or IPv6)
Moving up a layer, part of the Ethernet frame is what becomes the PDU for the internet or network layer, i.e. a packet.
This internet layer uses something known as the internet protocol which facilitates communication between hosts (i.e. different computers) on different networks. The two main versions of this protocol are known as IPv4 and IPv6. They handle routing of data via IP addressing, and the encapsulation of data into packets.
IPv4 was the de facto standard for addresses on the internet until relatively recently. There are around 4.3 billion possible addresses using this protocol, but we are close to having used up all those addresses now. IPv6 was created for this reason and it allows (through the use of 128-bit addresses) for a massive 340 undecillion (billion billion billion billion) different addresses.
Adoption of IPv6 is increasing, but still slow.
There is a complex system of how data makes its way from one end node on the network, through several other networks, and then on to the destination node. When the data is first transmitted, a full plan of how to reach that destination is not formulated before starting the journey. Rather, the journey is constructed ad hoc as it progresses.
Transport Layer — TCP/UDP
There are a number of different problems that the transport layer exists to solve. Primarily, we want to make sure our data is passed reliably and speedily from one node to another through the network.
TCP and UDP are two protocols which are good at different kinds of communication. If the reliability of data transmission is important to us and we need to make sure that every piece of information is transmitted, then TCP (Transmission Control Protocol) is a good choice. If we don't care about every single piece of information — in the case of streaming a video call, perhaps, or watching a film on Netflix — but rather about the speed and the ability to continuously keep that data stream going, then UDP (User Datagram Protocol) is a better choice.
There are differences between the protocols beyond simply their functionality. We can distinguish between so-called 'connection-oriented' and 'connectionless' protocols. For connection-oriented protocols, a dedicated connection is created for each process or strand of communication. The receiving node or computer listens with its undivided attention. With a connectionless protocol, a single port listens to all incoming communication and has do disambiguate between all the incoming conversations.
TCP is a connection-oriented protocol. It first sends a three-way handshake to establish the connection, then sends the data, and sends a four-way handshake to end the connection. The overhead of having to make these handshakes at the beginning and at the end, it's a fairly costly process in terms of performance, but in many parts of internet communication we really do need all the pieces of information. Just think about an email, for example: it wouldn't be acceptable to receive only 70% of the words, would it?
UDP is a connectionless protocol. It is in some ways a simpler protocol compared to TCP, and this simplicity gives it speed and flexibility; you don't need to make a handshake to start transmitting data. On the negative side, though, it doesn't guarantee message delivery, or provide any kind of congestion avoidance or flow control to stop your receiver from being overwhelmed by the data that's being transmitted.
Application Layer — HTTP
HTTP is the primary communication protocol used on the internet. At the application layer, HTTP provides communication of information to applications. This protocol focuses on the structure of the data rather than just how to deliver it. HTTP has its own syntax rules, where you enclose elements in tags using the < data-preserve-html-node="true" and > symbols.
Communication using HTTP takes the form of response and request pairs. A client will make a 'request' and it'll receive (barring some communication barrier) a 'response'. HTTP is known as a 'stateless' protocol in that each request and response is completely independent of the previous one. Web applications have many tricks up their sleeve to make it seem like the web is stateful, but actually the underlying infrastructure is stateless.
When you make an HTTP request, you must supply a path (e.g. the location of the thing or resource you want to request / access) and a request method. Two of the most common request methods are GET and POST, for requesting and amending things from/on the server respectively. You can also send optional request 'headers' which are bits of meta-data which allow for more complicated requests.
The server is obliged to send a HTTP status code in reply. This code tells you whether the request was completed as expected, or if there were any errors along the way. You'll likely have come across a so-called '404' page. This is referring to the 404 status code indicating that a resource or page wasn't found on the server. If the request was successful, then the response may have a payload or body of data (perhaps a chunk of HTML website text, or an image) alongside some other response headers.
Note that all this information is sent as unencrypted plain text. When you're browsing a vanilla http:// website, all the data sent back and forth is just plain text such that anyone (or any government) can read it. This wasn't such a big issue in the early days of the internet, perhaps, but quite soon it became more of a problem, especially when it came to buying things online, or communicating securely. This is where TLS comes in.
TLS or Transport Layer Security is sometimes also known as SSL. It provides a way to exchange messages securely over an unsecured channel. We can conceptually think of it as occupying the space between the TCP and HTTP protocols (at the session layer of the OSI framework above). TLS offers:
- encryption (encoding a message so only authorised people can decode it)
- authentication (verifying the identity of a message sender)
- integrity (checking whether a message has been interfered with)
Not all three are necessarily needed or used at any one time. We're currently on version 1.3 of TLS.
Whew! That was a lot. There are some really good videos which make the topic slightly less dry. Each of these separate sections are extremely complex, but having a broad overview is useful to be able to disambiguate what's going on when you use the internet.